时间:2016-02-24 12:34 来源:
我爱IT技术网 作者:佚名
欢迎您访问我爱IT技术网,今天小编为你分享的编程技术是:【.NET2.0抓取网页全部链接】,下面是详细的分享!
.NET2.0抓取网页全部链接
效果图
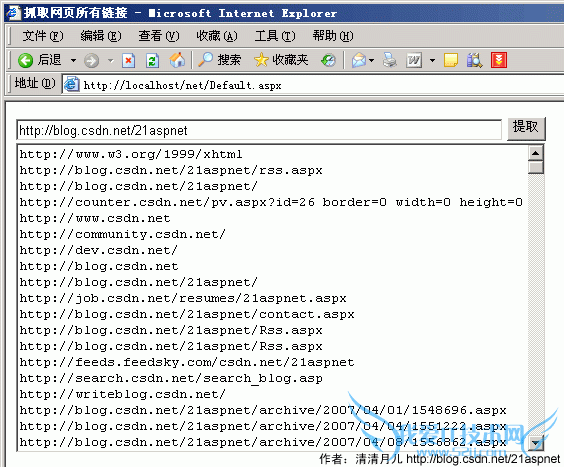
后台代码
|
以下为引用的内容:
using System;
using System.Data;
using System.Configuration;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.Collections;
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
}
}
protected void Button1_Click(object sender, EventArgs e)
{
TextBox2.Text="";
string web_url=this.TextBox1.Text;//"http://blog.csdn.net/21aspnet/"
string all_code="";
HttpWebRequest all_codeRequest=(HttpWebRequest)WebRequest.Create(web_url);
WebResponse all_codeResponse=all_codeRequest.GetResponse();
StreamReader the_Reader=new StreamReader(all_codeResponse.GetResponseStream());
all_code=the_Reader.ReadToEnd();
the_Reader.Close();
ArrayList my_list=new ArrayList();
string p=@"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex re=new Regex(p, RegexOptions.IgnoreCase);
MatchCollection mc=re.Matches(all_code);
for (int i=0; i <=mc.Count - 1; i++)
{
bool _foo=false;
string name=mc[i].ToString();
foreach (string list in my_list)
{
if (name==list)
{
_foo=true;
break;
}
}//过滤
if (!_foo)
{
TextBox2.Text +=name + "\n";
}
}
}
}
|
前台
以下为引用的内容:
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs" Inherits="_Default" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head runat="server">
<title>抓取网页所有链接</title>
</head>
<body >
<form id="form1" runat="server">
<div>
<asp:TextBox ID="TextBox1" runat="server" Width="481px"></asp:TextBox>
<asp:Button ID="Button1" runat="server" OnClick="Button1_Click" Text="提取" />
<br />
<asp:TextBox ID="TextBox2" runat="server" Height="304px" TextMode="MultiLine" Width="524px"></asp:TextBox></div>
</form>
</body>
</html>
|
以上所分享的是关于.NET2.0抓取网页全部链接,下面是编辑为你推荐的有价值的用户互动:
相关问题:怎么做抓取网页全部链接?
答:呵呵,楼上 兄弟够狠,等会我给你写个. >>详细
相关问题:怎样用PHP抓取整个网站的链接?
答:$html = file_get_html('http://www.google.com/'); // Find all links foreach($html->find('a') as $element) echo $element->href . ''; 不知道你PHP支持不支持 file_get_html这个函数 但是像你说那样的抓 肯定会超时的 >>详细
相关问题:C#抓取网站下的链接下的网页数据怎么做??
答:1读取此网站的页面源代码 2利用正则取得所有超连接的内容 3把取得的超连接内容循环,再次操作1,2的步骤,这次2中写逻辑你想要的 数据 ---读取网页源代码--- protected void Page_Load(object sender, EventArgs e) { string strtemp; strtemp =... >>详细
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-