欢迎您访问我爱IT技术网,今天小编为你分享的编程技术是:【Linux内核代码中的脏话统计】,下面是详细的分享!
Linux内核代码中的脏话统计
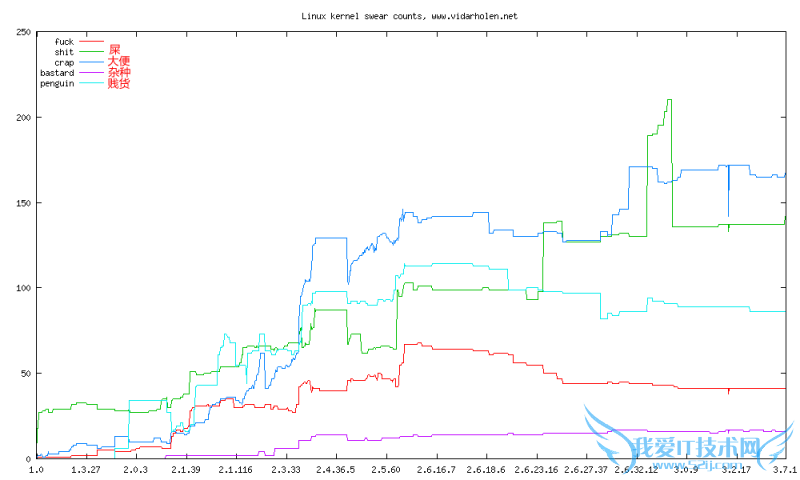
按脏话数/版本号统计
按脏话密度/版本号统计
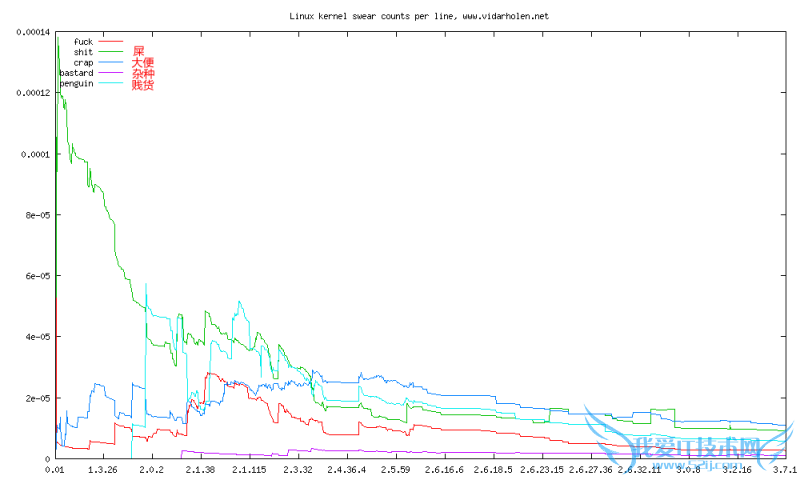
上图显示的是对Linux内核里的c,h和S源代码里的脏话统计结果,我会每月更新一次这些数据,当有新版本发布时也会更新一次。我是受the linux kernel fuck count的启发,但遗憾的是它里面的数据已经过期了。
从图中可以很明显的看出,自从2.4版开始,脏话的数量有大量的增加。然而,总的代码量也增加了很多,所以,总的来看,平均每行的诅咒密度是减少的。
介绍一下统计方法:不论任何地方出现的脏话词汇都会计入总数——出现在另一个词内也算。本来可以做的更合理些,但结果发现FreeBSD的正则表达式引擎有严重的内存泄漏问题,我也就没有再改进了。一行里对一个脏词可能会统计出多次,因为有时候一个程序员会遇到非常非常懊恼的一天。
你可以在找到这个脚本,但它写的实在是太乱了,不推荐。
以上所分享的是关于Linux内核代码中的脏话统计,下面是编辑为你推荐的有价值的用户互动:
相关问题:如何查看 linux 内核源代码
答:一般在Linux系统中的/usr/src/linux*.*.*(*.*.*代表的是内核版本,如2.4.23)目录下就是内核源代码(如果没有类似目录,是因为还没安装内核代码)。另外还可从互连网上免费下载。注意,不要总到http://www.kernel.org/去下载,最好使用它的镜像... >>详细
相关问题:linux 内核 源代码有多大
答:3.0版压缩成tar.gz包大概100M 2.6大概60M >>详细
相关问题:《Linux内核剖析》中任务数据结构中代码的含义
答:这是家庭作业题吗?怎么分到医疗健康类别里了? 到这儿可以找到答案: http://blog.csdn.net/jurrah/article/details/3965437 这儿有篇论文也可以参考一下: http://wenku.baidu.com/link?url=7KEWIbPLvxxSqzIq9IHa3_Kn02t_M5RrWb4QU-ULqs-634tL... >>详细
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-