欢迎您访问我爱IT技术网,今天小编为你分享的编程技术是:【修改一行SQL代码 性能提升了100倍】,下面是详细的分享!
修改一行SQL代码 性能提升了100倍
Nested Loop (cost=6923.33..11770.59 rows=1 width=362) (actual time=17128.188..22109.283 rows=10858 loops=1)
Buffers: shared hit=83494
-> Bitmap Heap Scan on context c (cost=6923.33..11762.31 rows=1 width=329) (actual time=17128.121..22031.783 rows=10858 loops=1)
Recheck Cond: ((tags @> '{blah}'::text[]) AND (x_key=1))
Filter: (key=ANY ('{15368196,(a lot more keys here)}'::integer[]))
Buffers: shared hit=50919
-> BitmapAnd (cost=6923.33..6923.33 rows=269 width=0) (actual time=132.910..132.910 rows=0 loops=1)
Buffers: shared hit=1342
-> Bitmap Index Scan on context_tags_idx (cost=0.00..1149.61 rows=15891 width=0) (actual time=64.614..64.614 rows=264777 loops=1)
Index Cond: (tags @> '{blah}'::text[])
Buffers: shared hit=401
-> Bitmap Index Scan on context_x_id_source_type_id_idx (cost=0.00..5773.47 rows=268667 width=0) (actual time=54.648..54.648 rows=267659 loops=1)
Index Cond: (x_id=1)
Buffers: shared hit=941
-> Index Scan using x_pkey on x (cost=0.00..8.27 rows=1 width=37) (actual time=0.003..0.004 rows=1 loops=10858)
Index Cond: (x.key=1)
Buffers: shared hit=32575
Total runtime: 22117.417 ms
这次查询共花费22s,我们可以通过下图对这22s进行很直观的了解,其中大部分时间花费在Postgres和OS之间,而磁盘I/O则花费非常少的时间。
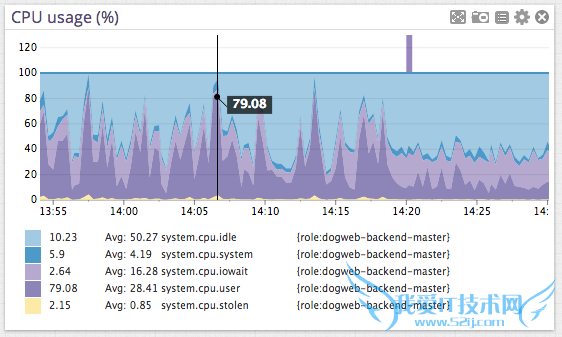
在最低水平,这些查询看起来就像是这些CPU利用率的峰值。在这里主要是想证实一个关键点:数据库不会等待磁盘去读取数据,而是做排序、散列和行比较这些事。
通过Postgres获取与峰值最接近的行数。
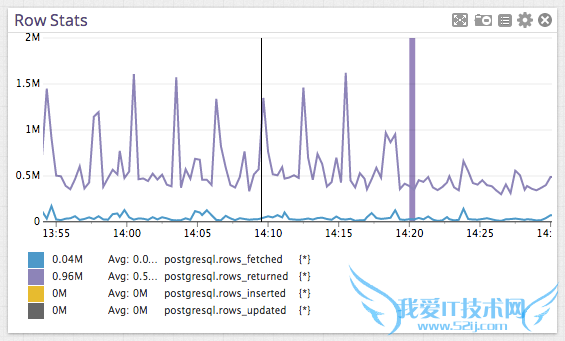
显然,我们的查询在大多数情况下都有条不紊的执行着。
Postgres的性能问题:位图堆扫描
rows_fetched度量与下面的部分计划是一致的:
|
1
2
3
4
5
|
Buffers: shared hit=83494
-> Bitmap Heap Scan on context c (cost=6923.33..11762.31 rows=1 width=329) (actual time=17128.121..22031.783 rows=10858 loops=1)
Recheck Cond: ((tags @> '{blah}'::text[]) AND (x_key=1))
Filter: (key=ANY ('{15368196,(a lot more keys here)}'::integer[]))
Buffers: shared hit=50919
|
Postgres使用位图堆扫描( Bitmap Heap Scan)来读取C表数据。当关键字的数量较少时,它可以在内存中非常高效地使用索引构建位图。如果位图太大,查询优化器会改变其查找数据的方式。在我们这个案例中,需要检查大量的关键字,所以它使用了非常相似的方法来检查候选行并且单独检查与x_key和tag相匹配的每一行。而所有的这些“在内存中加载”和“检查每一行”都需要花费大量的时间。
幸运的是,我们的表有30%都是装载在RAM中,所以在从磁盘上检查行的时候,它不会表现的太糟糕。但在性能上,它仍然存在非常明显的影响。查询过于简单,这是一个非常简单的key查找,所以没有显而易见的数据库或应用重构,它很难找到一些简单的方式来解决这个问题。最后,我们使用 PGSQL-Performance邮件向社区求助。
解决方案
开源帮了我们,经验丰富的且代码贡献量非常多的Tom Lane让我们试试这个:
|
1
2
3
4
5
6
7
8
9
10
|
SELECT c.key,
c.x_key,
c.tags,
x.name
FROM context c
JOIN x
ON c.x_key=x.key
WHERE c.key=ANY (VALUES (15368196), -- 11,000 other keys --)
AND c.x_key=1
AND c.tags @> ARRAY[E'blah'];
|
你能发现有啥不同之处吗?把ARRAY换成了VALUES。
我们使用ARRAY[...]列举出所有的关键字来进行查询,但却欺骗了查询优化器。Values(...)让优化器充分使用关键字索引。仅仅是一行代码的改变,并且没有产生任何语义的改变。
Nested Loop (cost=168.22..2116.29 rows=148 width=362) (actual time=22.134..256.531 rows=10858 loops=1)
Buffers: shared hit=44967
-> Index Scan using x_pkey on x (cost=0.00..8.27 rows=1 width=37) (actual time=0.071..0.073 rows=1 loops=1)
Index Cond: (id=1)
Buffers: shared hit=4
-> Nested Loop (cost=168.22..2106.54 rows=148 width=329) (actual time=22.060..242.406 rows=10858 loops=1)
Buffers: shared hit=44963
-> HashAggregate (cost=168.22..170.22 rows=200 width=4) (actual time=21.529..32.820 rows=11215 loops=1)
-> Values Scan on "*VALUES*" (cost=0.00..140.19 rows=11215 width=4) (actual time=0.005..9.527 rows=11215 loops=1)
-> Index Scan using context_pkey on context c (cost=0.00..9.67 rows=1 width=329) (actual time=0.015..0.016 rows=1 loops=11215)
Index Cond: (c.key="*VALUES*".column1)
Filter: ((c.tags @> '{blah}'::text[]) AND (c.x_id=1))
Buffers: shared hit=44963
Total runtime: 263.639 ms
以上所分享的是关于修改一行SQL代码 性能提升了100倍,下面是编辑为你推荐的有价值的用户互动:
相关问题:access表中如果修改了某个数据,就在这个数据后同...
答:不在窗体中操作: 需要Access 2007 或更高版本的Access才能在非窗体中完成―― 数据宏,可以让您在表中完成这个操作。 宏事件为 “更改前” 可以定义条件(如果需要的话),也可以这样 : 只要修改了任意数据,那么就把另一字段更新为当前日期与时间... >>详细
相关问题:这有点代码请大家帮我看看,我从数据库查询到的就...
答:查询出来的结果集默认是指向第一条的 根本没看到你有movenext的动作呀 当然只显示一条了 >>详细
相关问题:请教我的asp网页,修改链接数据库时,修改时只会修...
答:infolist1="select * from student " 这句话 指明 要sutdent表 但是未说明改哪行 那默认就是第一行了 1 可以用循环遍历着改 2 sql语句 加入条件 例如 id0 这样其实也是全部记录了 另外修改语句是Update 不是Select >>详细
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-