java教程:关于Unicode码的几个名词解释
【我爱IT技术网】3月13日IT技术:关于Unicode码首先说一下几个名词的解释:
Unicode是一种字符编码的方式,全称是Universal Multiple-Octet Coded Characrer Set,简称UCS。UCS用以规定如何用多个字节表示多种文字(字符编码),而用于规定传输UCS编码的规范称为UTF(UCS Transformation Format),UTF规范包括UTF-7,UTF-8,UTF-16。
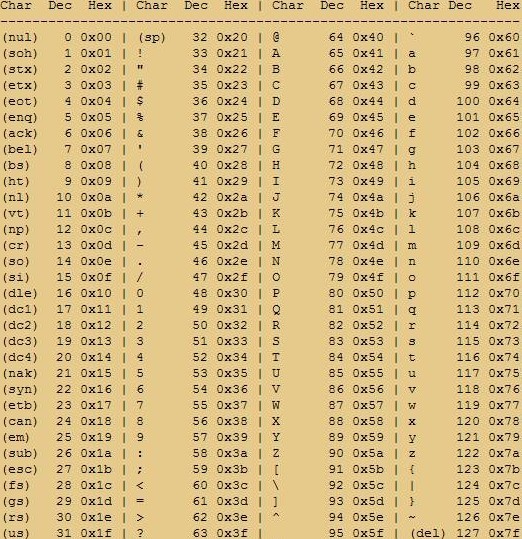
而UCS有两种格式:UCS-2和UCS-4。
我们现在要讨论的是UCS-4,它分为128个group,每个group又分为256个plane,每个plane分为256个row,每个row包括256个cell。
其中,高两个字节为0的编码称为BMP(Basic Multilingual Plane),将UCS-4高位的两个字节砍掉就是UCS-2。
字节序的概念
现在让我们来考虑,既然我们现在存在多种编码形式,例如ANSI,Unicoe,Unicode big endian,那么系统是如何辩别文件采用的到底是何种编码的呢?假设系统扫描文件时,碰到两个字节,它是如何判断这两个字节表示的是一个字符,还是一个字符的前两个字节(在UCS-4中)?
这就是通过字节序标记(Byte Order Mark)来识别。它分为两种:big endian(俗称大尾)和little endian(小尾)。
有两个十分重要的概念需要弄明白的:
1。代码单元(code unit):指的是BMP中的字符
2。代码点(code point):指的是编码表中某字符对应的代码值,是一个十六进制数。
现在让我们考虑一下:如果我们在程序中使用char,会出现什么样的问题。
因为Java中使用UTF-16编码,即:用4个字节表示一个字符编码,但在Java中,char类型只有16位,那么在使用char时有可能将4个字节截断,从而产生错误。如果非要使用的话,建议使用codePointAt(index)方法。
本文来源 我爱IT技术网 http://www.52ij.com/jishu/320.html 转载请保留链接。
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-