Oracle优化经验谈─运行速度优化与内存配置
本文将分别从:内存管理、Row chaining与Row migration、实体文件规划、SQL优化等四个角度,探讨如何解决连线数量增加后,面临Oracle数据库系统效率与管理问题。
话说某横跨两岸三地集团,过去10年业绩成长显着,大陆工厂人员也由1000来人成长至10000人,7年前导入以Oracle为数据库的ERP,经由MIS的修修补补,功能面也已发展成熟。
不过由于公司持续的扩厂,使用ERP人员不断增加,最近大陆ERP的使用反而发生许多不稳定状况,包括:
●整体运作速度变慢。
●ERP明明没问题,但就是会报错,特别是人多的时候。
●MIS说ERP主机的内存够用,不应该发生这样的问题。
●相关插件系统很容易就被Oracle自动断线或是连不上。
扣除两岸专线带宽不足、或是ERP有Bug因素后,还需再考量的就是数据库问题。但对大部份熟悉SQL Server‘下一步’的MIS而言,Oracle可就没那么容易进行优化!
Oracle database与SQL Server至少有几个不同处:
●一个SQL Server instance,可以安装多个数据库(除非你愿意在一个操作系统中,每一个数据库就安装一套SQL Server,并开立不同的Instance);Oracle database server则不同,一个数据库就是一个Instance。
●同一个Instance的SQL Server所有数据库,共用该Instance所有内存;Oracle database则是每一个数据库有各自的内存。
●SQL Server有集中的自我管理模式;Oracle却得由DBA自行优化。
●SQL Server没有太多参数可以让DBA进行优化;Oracle则有成堆的参数让你进行数据库优化与控制。
以下笔者将就相关参数,以及Oracle提供的统计功能,分别从:内存管理、Row chaining与Row migration、实体文件规划、SQL优化等四个角度,探讨如何解决人员增加之后,所面临的Oracle效率与管理问题(注意:Oracle 11g中有很多工具可以协助DBA优化,但对大多数5、6年前已导入ERP的公司,数据库可能还停留在Oracle 9i或更早之前的版本,所以笔者尽可能使用SQL解说,不刻意引用Oracle 11g的Oracle Enterprise Manager数据与画面来分析)。
了解你的操作系统以及Oracle database版本信息
不同的Oracle database版本所提供的优化机制也各不相同,例如Oracle 9i提供各自SGA、PGA优化参数,但到了Oracle 11g,则提供了更进阶的整体内存优化参数。
不同操作系统以及版本也一样会影响优化方式,例如Oracle 9i在Linux的使用上,如果为32位元版本,则SGA有1.7G使用的限制,但如果为64位元版本,则无此限制。(图1、图2、图3)
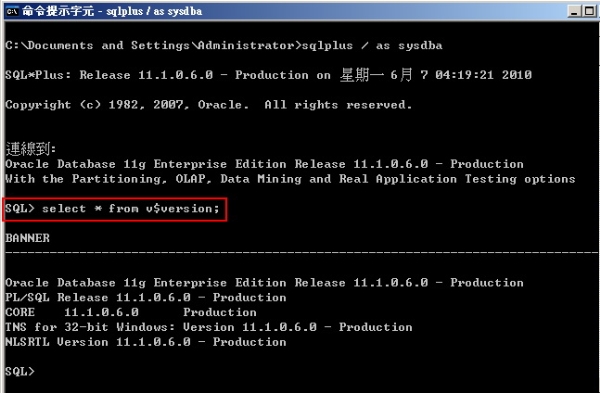
▲图1 查看Oracle database版本。
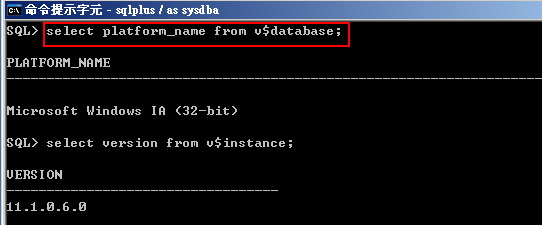
▲图2 查看Oracle database安装平台信息。
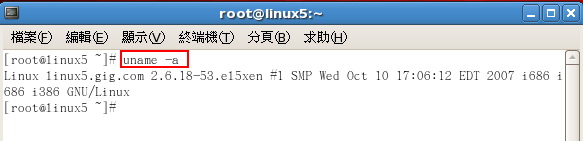
▲图3 查看Linux版本,以及为32或64位元版本。
平时有多少程序会连接到Oracle database
谈这个问题之前,且让我们先了解Oracle database的内存组成:System Global Area(以下简称SGA)与Program Global Area(以下简称PGA)。(图4)
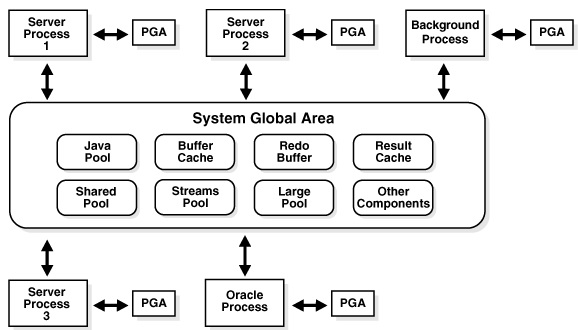
▲图4 Oracle Instance内存组成。
SGA中最重要的3个组成为:
●Database buffer cache:储存从实体文件中读出来的数据。
●Redo log buffer:储存用户改变数据的信息,当用户进行Roll back 时即是靠Redo log buffer的数据。
●Shared pool:包含Library cache(储存执行SQL过程所需的收集、分解、解析SQL所有信息)、Dictionary cache(储存有关于Table、View等结构相关信息)、Result cache(储存执行结果)。
这些是给Oracle Instance共用的内存,‘所有’用户在进行数据库存取时都会‘共用’SGA。
至于PGA则如其名,是给每一个Session所对应的Background process或Server Process使用,每一个Session都对应一块‘私有内存’,彼此互不共用,当Session结束时这PGA也会被回收。
PGA是用来执行Process SQL statement,并包含用户登陆以及用户的相关信息,主要包含以下2部份:
●Session memory:储存有关于Session variable,例如用户登陆信息。
●Private SQL Area:包含变量数据、查询状态、查询执行结果存放区(Query execution work area,例如SQL中的Order by、Group by运行时的数据暂存区)。
从以上的理论说明中可以明确感受到:SGA太小,则与数据读取有关的部份速度会变慢;而PGA太小,则SQL运算、特别是与Order by、Group by有关的运算会变慢。那么这与有多少程序会连接到Oracle有何关系?
程序建立Session、Session建立一个或多个Process(或一个Process对应多个Session)、每一个Process会耗用一定的PGA,但在Oracle设计中PGA的总内存是被参数所控制的,所以Session越多、Process越多,每一个Process所能分到的PGA就会越少,SQL的运算就会变慢!Oracle针对Process数量可以进行参数设置,而经由此参数,又可以限定所能连接的Session数,一般算法为:sessions=1.1*processes + 5。
Process与Session这两者互为一体两面。Process设置太大,那么就要给予更多的PGA,否则程序的SQL运算会变慢;设置太小。如果某天你的用户连线到Oracle Instance拒绝连线,或许就是因为Process设置不够大,导致可以连线的Session不够多。
有关于目前Oracle instance中有多少Session,可以用以下的SQL抓取:
select count(*) from v$session
有关于目前Oracle instance中有多少Process,可以用以下的SQL抓取:
Select count(*) from v$process
该如何配置内存?该配多少内存?
Oracle配置内存的方法依不同版本而有不同作法:例如Oracle 11g你可能只要设置总内存参数memory_target,即可由Oracle Instance自行进行内存配置;但在Oracle 9i则是SGA与PGA的内存需各自设置;或是不管在哪一个版本,你都可以进行全手工设置!
当主机有足够内存时,内存配置不会是大问题(只要把所有与内存有关的参数都放大即可),但若主机的总内存不多,或是如前述因版本问题,碰到SGA内存不得超过1.7G限制、session总数破2000时,内存的管理可能就是大问题。
笔者建议采用SGA与PGA分开优化的半自动内存管理策略较有弹性,在此情况下不使用memory_target参数,而改用以下参数设置:
sga_max_size
设置分配给SGA的总内存上限,当sga_max_size的内存量大于分配给SGA相关参数内存总合时,多出来的部份,会分配给share_pool_size:
●buffer_cacahe_size:理论上越大越好,日后读取相同数据时,可以由内存中读取,不需读取实体文件。
●shared_pool_size:理论上越大越好,日后有相同的SQL需要执行时就不需要重新解析。
●log_buffers:对数据库的任何修改都按顺序被记录在该缓冲,然后由LGWR 进程将它写入Disk,但正常情况下LGWR的写入条件中包含有一条‘大于1M重做日志缓冲区未被写入Disk’,因此我们可以说大于1M的log buffer值意义并不大。
pga_aggregate_target
设置PGA可用总内存数量目标(也就是说:实际Oracle instance使用时有可能超出一点点,但不可以超过太多),当pga_agreegate_target够大时,每一个用户所分配的private sql area就会比较大,如有Order by 或Group by时计算自然较快。
例如pga_aggregate_target设为300MB,5个用户连接时每个用户可能分发10MB的PGA内存,共分发50MB的PGA内存;300个用户连接时每个用户可能分发1.3MB的PGA内存,共分发390MB(当用户连接多时, Oracle会降低每个用户的PGA内存使用量)。
那么SGA相关参数该如何设置?首先我们得先了解目前的SGA设置状况,可以由图5中的指令得知现行SGA的分配状况。
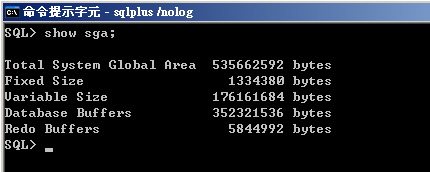
▲图5 SGA现行配置状况。
至于多少的内存才算是足够?对任何DBA而言都没有标准答案,但Oracle针对这个问题使用了如表1的命中率的观念来说明。

另外,如果你是使用如Oracle 11g等较高版本,并有安装Oracle Enterprise Manager,则你可以引用图6、图7的数据来进行SGA、PGA内存的规划(当内存增加,并无法降低数据读取次数、或提高执行速度时,代表该点即为内存设置的最佳值)。
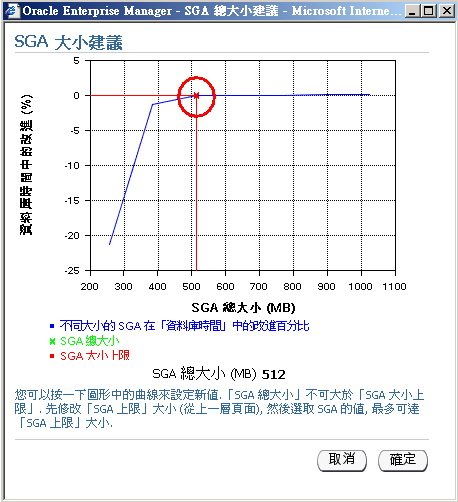
▲图6 由Oracle依内部统计数据建议的SGA最佳值。
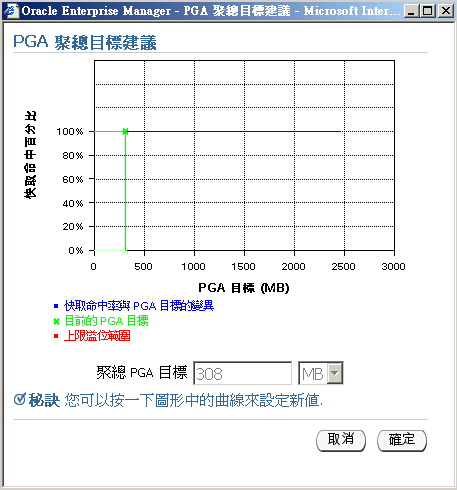
▲图7 由Oracle依内部统计数据建议的PGA最佳值。
关于Row chaining、Row migration对数据读写速度的影响
在现实的运作环境中,数据并非如字典一般规矩的排列在实体数据库中!至少有以下因素会导致数据的存放异常:
●Row chaining:当Insert一笔较长的数据,但该Data block又无法容纳该笔数据时,则该笔数据会存放在一个或多个Data block。日后要读取该数据时,则需读取多个Data block造成速度变慢。
●Row migration:当Data block将用完,如果对已有的数据Update为较长的数据,则Oracle会将原有的数据移到一个新的Data block,而只在原有的数据空间存放一个指针(但不存放数据)指到新的存放位置。日后要读取该数据时,则需读取多个Data block(读到原有的Data block,再经由指针读到真正数据存放处)造成速度变慢。
Row chaining与Row migration会让Insert、Update的动作变慢(需跨多个Data block);也会让Select的过程读取更多实体数据,但在实务上又无法避免,一般而言,你可用以下的方法来改善:
●加大Data block。例如Data block为4K,但Row的平均长度为6K时,加大Data block可以有效的改善Row chaining的问题。需注意的是:已建立的Tablespace, Data block的大小是不能再更改的,如果要进行这样的处理,你所能做的是:设置参数档db_nk_cache_size参数以满足读取较大空间的需求;建立新的Tablespace,并在建立过程声明较大的Data block;将这类的Table移动、指定存放到该Tablespace。
●加大PCTFREE参数的大小。将Table 的PCTFREE放大,多保留一些空间供日后Update使用,此方法可以降低Row migration的情况。
●针对Row chaining或Migration严重的Table定期进行Export、Import。
有关于Table row chaining或Row migration的情况,可以利用以下的SQL抓取数据分析(注意:对Oracle Instance而言,Row migration被视为Row chaining的一种特例,并没有独立分类):

如何进行实体文件规划
典型的Oracle实体文件组成包括如下:
●Datafile:负责储存来自User所输入的数据、相关索引、以及其他DDL、DML数据,每一个数据库都会有一个或多个Datafile。当User有存取数据需求时会经由Oracle instance先进行需求分析,再由Oracle instance内的Process,进行Tablespace所对应的Datafile数据的存取。
●Redo log file:一份交易的记录信息,每当Oracle instance对数据库进行数据的新增、删除、修改时,就会将该交易记录写入Redo log file。若系统发生异常状况,系统即可以Redo log file中的信息,针对Oracle失效当时的交易进行Forward commit或Roll back commit的Recovery处理。
●Archived file:已归档、已Commit交易过程记录文件(即已满的Redo log file),当有Recovery需求时,Oracle可以参考Archived file的交易过程记录信息,将Oracle数据库Recovery到特定时期。
●Control file:储存的是有关Oracle的相关核心信息,如有那些Datafile、Control file、名称为何、存放于何处。Oracle于启动过程会读取本档的数据。
●InitORA_DB.ora / SPFILE:所存放的信息包括建立数据库过程需参考的信息,以及后续数据库的运作信息。
●Alter file / Trace file:存放预警、追踪的信息。每一个Server与Background process,都可以将相关的警示与错误信息写入Trace file或Log file。
这些实体文件的存放位置,对于数据库的运作速度也会有影响。一般而言建议将Datafile分别建立在不同的硬碟上,例如存放Index的Tablespace所对应的Dataflie存放在A硬碟,存放数据的Tablespace所对应的Datafile存放在B硬碟,这样在多人连线、多用户存取时由于各硬碟可以同时运作存取数据,因此会有更好的效率。
另外,Datafile、Redo log file、Archived file最好不要放在同一个硬碟,以避免同一时间、同一硬碟要同时读写不同数据。同时,Redo log file及Archived file都是做为数据库复原的重要依据,如果将这3种数据实体文件存放在同一个硬碟,当硬碟损毁将会造成数据无法复原。
从如何写好SQL开始
从Oracle Instance的角度来看,‘好’SQL代表能善用DBA已建立的Index、尽可能不要有Table scan动作、能有少一点的实体文件读取;另一方面,资深的程序开发人员以及DBA通常也都会遵守以下规则:
●Primary key建立Index。
●Where引用到的栏位建立Index。
●Join过程中的引用的条件建立Index。
●必要时以Cluster建立Table。
●使用多一点的Where条件,以让SQL少抓一些数据。
●Select的过程,指名栏位名称,少用‘Select *’之类的写法。
问题来了:你能用数据证明,你所写的SQL是以所预期的方式在数据库内部运行?DBA所建立的Index有发挥作用?
不管Oracle或SQL Server都有类似Query optimizer,从数据库本身角度(而不是‘人’的角度),进行SQL的拆解(为SQL plan),并找到其认为最节省成本的执行方式。
在Oracle中你可以用以下方式查看SQL plan:
●建立存放SQL plan的Table。
●将SQL Plan存放至该Table。
●读取SQL Plan的数据并显示。
图8即为笔者解析某SQL的SQL Plan,发现该SQL会引用DBA所建立的Index来进行数据查询,符合当初建立Index的目的。
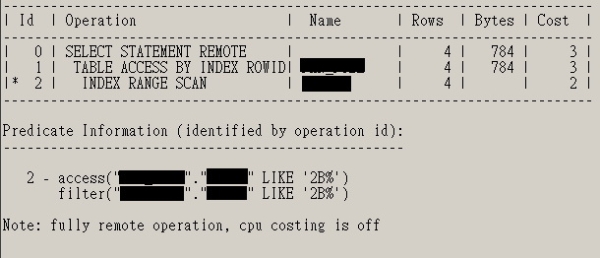
▲图8 由Oracle内部所解析的SQL Plan。
结语
Oracle Database运作速度优化与内存配置,并无绝对的标准!除了靠DBA平日对Oracle Instance运作速度观察、用户反馈之外,Oracle仍提供一些数字指针(如Cache命中率)与建议方案供DBA做为优化依据。
另外,再配合实体文件位置规划、Row chaining问题处理、SQL分析与优化,就可以大幅降低Oracle Instance所造成的运作速度低下与异常情况
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-