时间:2016-04-01 17:18 来源: 我爱IT技术网 作者:佚名
在数据库中,面对一组重复度很高的数据时,若想提取其中出现过哪些数据,去掉冗余项,那么我们可以有group by语句来实现,在Excel中,若想实现这个功能,就需要借助数组公式和Excel函数来实现,数组公式用于产生一组结果,函数用于控制结果。
前期准备工作(包括相关工具或所使用的原料等)
Microsoft Excel
一组存在冗余度的数据
详细的操作方法或具体步骤
首先我们有一列数据,B2:B14,其数据有重复

在D2输入公式=INDEX($B:$B,MIN(IF(COUNTIF($D$1:D1,$B$2:$B$14),2^20,ROW($B$2:$B$14))))&""
$B:$B是数据源所在的列的引用
$D$1:D1,这个需要解释,对于公式所在的单元格,它必须能够包含该单元格之前所有已经产生结果的区域,例如当公式填充到D4单元格时,这个区域就是D1:D3,能包含D2单元格和D3单元格已经产生的两个结果。如果我们从D列的第n行(n>=2)开始写公式,那么这里就可以写$D$k:Dn-1,这里的k取0到n之间的任何值都是可行的
$B$2:$B$14是数据所在的区域
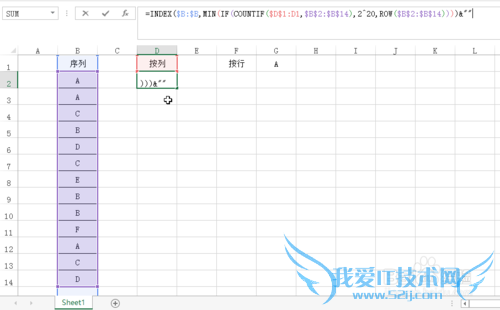
输入完后,不要急于退出公式编辑模式,同时按下键盘Ctrl+Shift+Enter,生成数组,表现为公式两端出现花括号
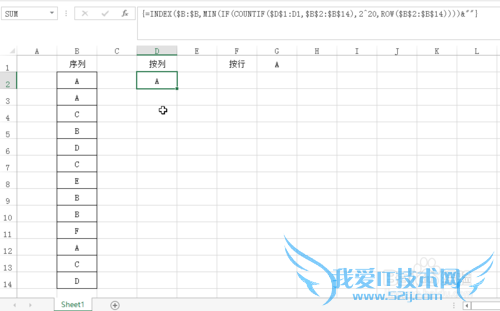
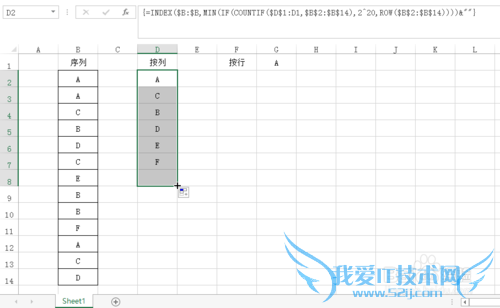
利用填充柄将D2向下拖动,得到结果
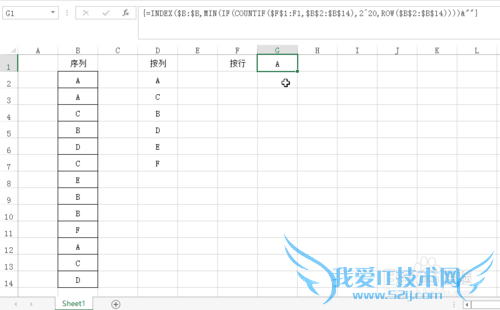
按行输出结果需要修改公式:=INDEX($B:$B,MIN(IF(COUNTIF($F$1:F1,$B$2:$B$14),2^20,ROW($B$2:$B$14))))&""
这里主要将之前的$D$1:D1改为了$F$1:F1,即与公式所在单元格处于同一行
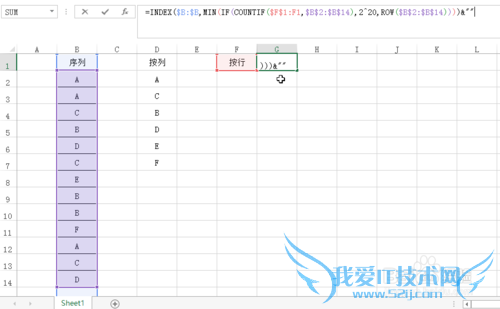
同样同时按下键盘Ctrl+Shift+Enter,生成数组
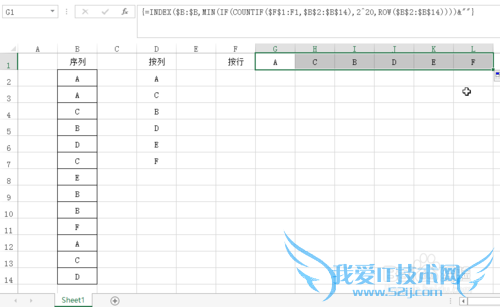
填充柄向右拖动,得到结果
 经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。作者声明:本文系本人依照真实经历原创,未经许可,谢绝转载。
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。作者声明:本文系本人依照真实经历原创,未经许可,谢绝转载。
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-