时间:2016-04-02 22:13 来源: 我爱IT技术网 编辑:52微风
百度搜索引擎的原理其中之一就是定期的派出网络爬虫到互联网上去爬取网页.我这里用java写了一个最简单的小程序来实现这一功能.
前期准备工作(包括相关工具或所使用的原料等)EclipseJDK 1.6EditPlus 详细的操作方法或具体步骤
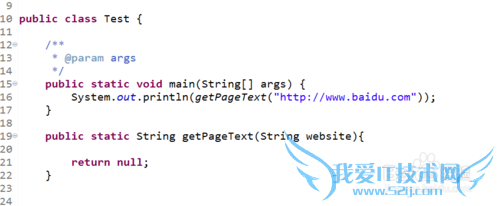
我希望输入一个有效的网址后返回这一网址下的网页源码,则有代码如图:
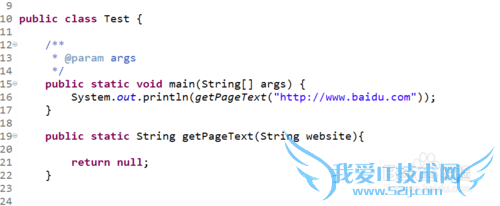
通过网址连接到指定的网址
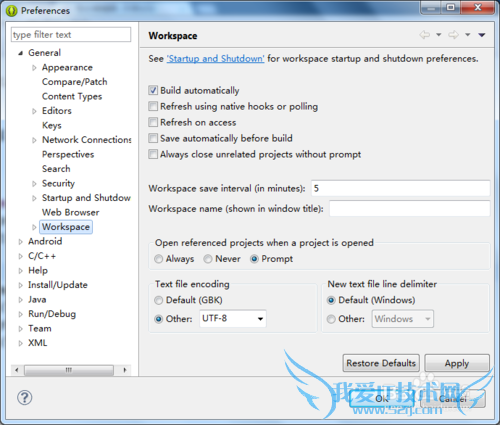
在运行之前把开发空间的的编码改为UTF-8,否则编译执行返回的网页中的中文会变成乱码
连接成功后通过连接对象得到输入流,读出输入流就可以得到网页代码
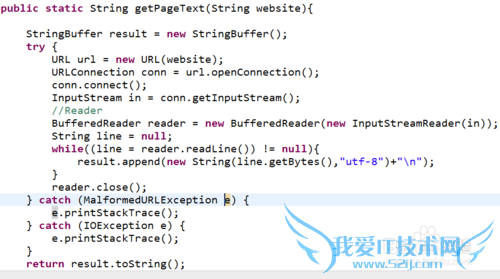
运行后得到的网页代码如下
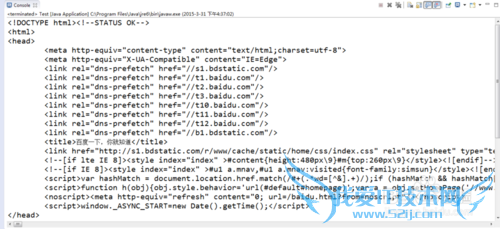
把返回的代码复制到EditPlus中运行一下看看
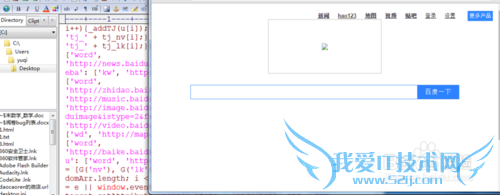
注意事项运行的结果百度的logo之所以没有是因为没有路径中没有http:,只有在服务器上才可以看经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。作者声明:本教程系本人依照真实经历原创,未经许可,谢绝转载。
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-